
ABAP Internal Tables: Standard, Sorted, and Hashed Table
Internal tables are like temporary tables that you can define and use throughout your ABAP program, you can create internal tables based on structures from SAP standard tables, custom tables or even data types such as i (integer) or string.
You can use internal tables to store and manipulate the records retrieved from SAP tables and display the data to the users, or you can use the data from the internal tables (temporary tables) to update the records in SAP tables.
In this tutorial we will go through all types of internal tables and how you can use them properly in the ABAP program.
| Tutorial Objectives |
| 1. Understand different types of Internal tables |
| 2. Know how to use internal tables in ABAP program |
| Prerequisites |
| 1. SAP System Access: SAP GUI, ECC |
| 2. Authorization: Developer role, TCODE: SE38 |
Different Types of Internal Tables in ABAP
There are different types of internal table that you can use for different purposes such as STANDARD TABLE, SORTED TABLE and HASHED TABLE, now let’s talk about the first type of internal table which the STANDARD TABLE.
1. Standard Table Type For Your Basic Usage
Standard Table is a type of internal table that relies on primary table index for data access and does not have primary keys by default. The Standard Table type is perfect for small datasets where the number of entries is limited, and the access patterns are simple.
The Basic Syntax
DATA it_temp TYPE | TABLE OF | STANDARD TABLE OF | <table_name>.Standard Table Type data will not get sorted
Because the lack of primary keys in this type of internal table, the records you retrieved into the internal table will not get sorted by any keys so you’d need to sort it manually. Take a look at this code below, the IT_SCARR internal table will not get sorted by the SCARR primary key which is CARRID.
data : it_scarr type standard table of scarr,
wa like line of it_scarr.
select * into table it_scarr from scarr.
loop at it_scarr into wa.
write: / 'CARR ID:', wa-carrid, 'CARRIER NAME:', wa-carrname.
endloop.Here’s the result
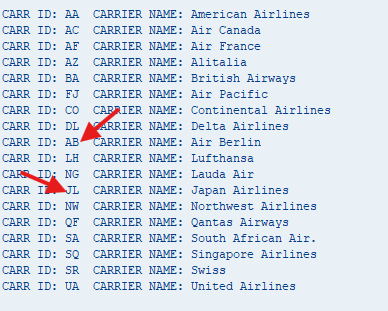
As you can see, the CARR ID is not sorted properly so you’d need to do it manually in the SELECT statement using ORDER BY CARRID or sort the internal table manually using the SORT statement as shown below.
sort it_scarr by carrid.Doing this kind of additional sorting will have some impacts to the performance of your program.
Standard Table uses linear search
Standard Table type also uses linear search when accessing the data. it means that the table searches for data by checking each entry sequentially from the beginning of the table to the end until a match is found.
The code below will show you how to search for a record in a standard table.
data: it_scarr type standard table of scarr,
" or you also use below declaration
"it_scarr type table of scarr
wa_scarr like line of it_scarr.
select * into table it_scarr from scarr.
read table it_scarr into wa_scarr with key carrid = 'PP'.
if sy-subrc = 0.
write: 'Airline found:', wa_scarr-carrname.
else.
write: 'Airline not found'.
endif.
How linear search works?
READ TABLE: When searching for CARRID = ‘PP‘, the system starts with the first entry and checks each subsequent entry until it finds a match or reaches the end of the table.
Performance Impact: If the matching record is at the end of the table or does not exist, the system must scan the entire table.
TYPE TABLE OF or TYPE STANDARD TABLE OF?
In our previous tutorial on how to update internal table we use the ( TYPE TABLE OF ) instead of ( STANDARD TABLE OF ) syntax to declare the internal tables. This statement ( TYPE TABLE OF ) is a generic statement that will implicitly create STANDARD TABLE by default. So keep in mind that both statements create the same type of internal table which is the STANDARD TABLE.
2. SORTED TABLE Type For Automatic Sorting
If Standard Table doesn’t have any primary keys, then Sorted Table is a type of internal table where the data is always maintained in a sorted order based on the primary key. You can either defined the primary key explicitly or it will be determined automatically from the table structure.
Basic Syntax
DATA: lt_sorted TYPE SORTED TABLE OF <your_structure>
WITH UNIQUE | NON-UNIQUE KEY <key_field>.Code Example
data : it_scarr_sorted type sorted table of scarr with unique key carrid,
wa like line of it_scarr_sorted.
select * into table it_scarr_sorted from scarr.
loop at it_scarr_sorted into wa.
write: / 'CARR ID:', wa-carrid, 'CARRIER NAME:', wa-carrname.
endloop.Here’s the result

As you can see, the result is automatically sorted by its primary key which is CARRID without any additional steps like adding ORDER BY or SORT the internal table.
Sorted Table uses binary search
The Sorted Table has a built-in binary search algorithm, enabling faster data retrieval compared to the linear search used in Standard Tables.
How Binary Search works?
Binary Search is an efficient searching algorithm that works by repeatedly dividing a sorted dataset in half (it’s possible because the data is already sorted) until the target value is found or the search range is exhausted. This algorithm significantly reduces the number of comparisons required compared to a linear search, making it faster for large datasets.
Binary Search: The Nearest Neighbor Lookup
Imagine you’ve split the records into two sets. The algorithm then automatically decides which set is nearer to your target key and performs the search within that set only. This approach reduces the search space by half, effectively improving the speed by approximately 50% as shown below.
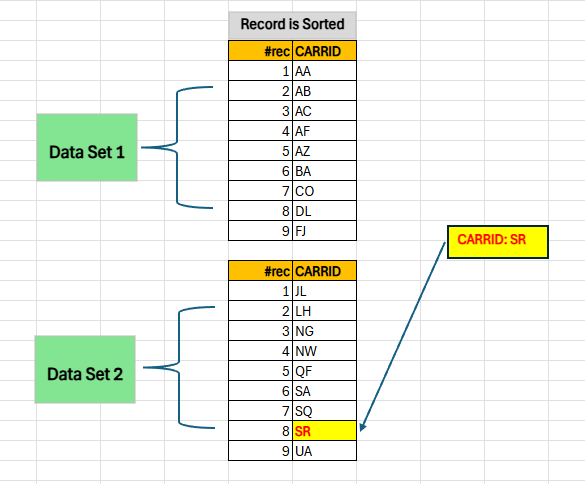
3. Hashed Table Type To Handle Large Data
A Hashed Table is a special type of internal table in ABAP that uses a hashing algorithm to store and retrieve data efficiently based on unique keys or hashed keys.
Basic Syntax
DATA: it_hashed TYPE HASHED TABLE OF ekko WITH UNIQUE KEY ebeln.Hashed tables are designed for a fast, key based access, making them ideal for scenarios where frequent lookups are required in a large datasets. But unlike Sorted or Standard Tables, hashed tables do not maintain a physical order of entries.
So what is hashing algorithm?
A hashing algorithm is basically a mathematical function that converts input data with keys into a fixed size string or number (called the hash value or hash code). This hash value is stored in the memory then used to index or locate the data in a collection, such as a hashed table, in a constant search time. So it doesn’t matter if you have 10000 or 1000000 records, the search time will always constant.
Because the data is stored in the memory so it requires more memory compared to Standard or Sorted Tables due to the hash table structure.
Summary: Comparing Standard Table, Sorted Table and Hashed Table
| Feature | Standard Table | Sorted Table | Hashed Table |
|---|---|---|---|
| Search Algorithm | Linear Search | Binary Search | Hash based keys |
| Data Structure | Unsorted records | Sorted by its keys | Stored using hash algorithm |
| Table Keys | NON-UNIQUE (You cannot specify unique key) | UNIQUE and NON-UNIQUE | UNIQUE key only |
| Access Time | Depends on # of records | Depends on # of records (proportionally) | Independent of the # of records (constant) |
| Memory Usage | Low | Moderate | High |
| Scenarios | Small datasets | Medium datasets | Large datasets |
| Advantages | Simple, low memory usage | Automatic sorting, faster search | Faster access for large datasets |
| Disadvantages | Slow for large datasets, Linear search resulting more overheads | Insertions are slower | Cannot do sequential access, memory overhead |
Internal Tables Takeaways
- Standard Tables: Perfect for simple, small datasets where sequential access suffices.
- Sorted Tables: Useful when frequent lookups, range queries, or sorted data is needed. (don’t use it for insertion)
- Hashed Tables: Ideal for fast, key based lookups in large datasets with unique keys.
Share this tutorial with Fellow Geeks!TIPS: The tables that I’m using in this lesson is from SAP Mockup table called the FLIGHT Tables, if these tables are empty in your system then you can generate the FLIGHT tables first.