
How To Get 99% Faster With Parallel Cursor
When processing header and details records, we often used NESTED LOOP to update certain records from inside the loop. Unfortunately this technique will lead to significant performance issues, especially when dealing with large datasets.
This method (NESTED LOOP) slows down your program and impacts efficiency and that’s why we will learn how to implement another technique, which is Parallel Cursor to overcome this issue.
Later in this tutorial, we will conduct a performance test to compare the effectiveness of these two methods for updating internal table records.
| Learning Objectives |
| 1. Learn different ways to process header and details data in an internal table. |
| 2. Comparing NESTED LOOP and PARALLEL CURSOR to see which one is better |
| Prerequisites |
| 1. SAP Access: SAP GUI, ECC. |
| 2. Authorization: Developer role, TCODE:SE38. |
Basic Nested Loop Scenario
Now here’s an example of a nested loop scenario: We have IT_EKKO, which contains Purchasing Order Header records, and IT_EKPO, which holds Purchasing Order Details. The goal is to fetch the PO details corresponding to the PO Header numbers and store them in the IT_PO internal table.
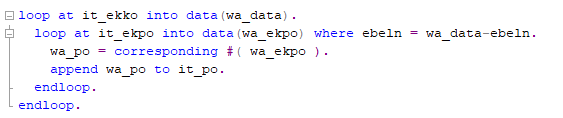
The Problem With Nested Loop
- For every entry in it_ekko, the entire it_ekpo table is scanned. ( n+1 loop will scan the inner table back from the beginning)
- If IT_EKKO has 1,000 entries and IT_EKPO has 10,000 entries, the loop executes 1,000 x 10,000 = 10 million iterations.
But what if you could reduce the program’s runtime by 99%? Parallel Cursor offers the solution!
Parallel Cursor To The Rescue
The Parallel Cursor technique solves the performance issues caused by nested loops by avoiding repeated scans of the inner table. Instead of starting from the beginning of the inner table (IT_EKPO) for every outer loop iteration (IT_EKKO).
The Parallel Cursor uses sorted data and a pointer-based approach (via sy-tabix) to locate the matching records (by using Binary Search). This ensures that each new iteration starts from the last processed record position, rather than restarting from the beginning.
Here’s the example of Parallel Cursor.
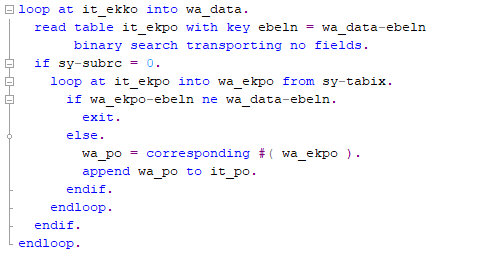
As you can see, the inner table (IT_EKPO) iteration uses FROM sy-tabix to start processing from the position found by the binary search. This ensures that the loop begins directly at the first matching record for the current EBELN in wa_data-ebeln, skipping over unrelated records at the start of the table.
Here’s the full ABAP source code example
data: l_start type timestampl,
l_end type timestampl,
l_result_nest type timestampl,
l_result_para type timestampl,
l_compare type p DECIMALS 2,
l_winner type c LENGTH 20.
*& For this testing purpose, I'm using standard table type
data: it_ekko type table of ekko,
it_ekpo type table of ekpo,
nrec type p DECIMALS 2.
*& CHANGE THE TABLE TYPE INTO SORTED TABLE
*& If you're using sorted table type the nested loop performance
*& will increase dramatically, but the parallel cursor still wins
*& at around 15% faster than nested loop.
*data: it_ekko type sorted table of ekko with UNIQUE KEY ebeln,
* it_ekpo type sorted table of ekpo with NON-UNIQUE KEY ebeln,
* nrec type p DECIMALS 2.
types:
begin of typ_po,
ebeln type ekko-ebeln,
lifnr type ekko-lifnr,
ebelp type ekpo-ebelp,
matnr type ekpo-matnr,
menge type ekpo-menge,
end of typ_po.
data: it_po type table of typ_po,
wa_po type typ_po.
*& Get the PO header and PO Details records
*& in this example we will limit the header to 6000 rows
select * into table it_ekko from ekko up to 6000 rows .
if it_ekko is not initial.
select * into table it_ekpo from ekpo
for all entries in it_ekko
where ebeln = it_ekko-ebeln.
endif.
*& Sort the internal table
*& If you're using SORTED TABLE TYPE then you don't
*& need this line anymore
sort: it_ekko by ebeln, it_ekpo by ebeln ebelp.
*& Start The Nested Loop
get time stamp field l_start.
loop at it_ekko into data(wa_data). "PO Header
loop at it_ekpo into data(wa_ekpo) where ebeln = wa_data-ebeln.
"IT_EKPO will be scanned from the TOP (first record) on each iteration
wa_po = corresponding #( wa_ekpo ).
"We append the details into IT_PO internal table
append wa_po to it_po.
endloop.
endloop.
get time stamp field l_end.
*& Calculate the runtime for nested loop
l_result_nest = l_end - l_start.
nrec = lines( it_po ).
write :/ '(Nested Loop)'.
write :/ '#Records:', nrec, 'Time:', l_result_nest, 'seconds'.
skip.
refresh: it_po.
*& Start the Parallel Cursor
get time stamp field l_start.
loop at it_ekko into wa_data. "PO Header
"The read table is using binary search for faster reading
"and transporting no fields because we only need the position of the
"record (sy-tabix)
read table it_ekpo with key ebeln = wa_data-ebeln
binary search transporting no fields.
if sy-subrc = 0.
"Start the inner table iteration using the matching record position
loop at it_ekpo into wa_ekpo from sy-tabix.
"this is the exit handler when the detail ebeln <> header ebeln
if wa_ekpo-ebeln ne wa_data-ebeln.
exit.
else.
"add to internal table when detail ebeln = header ebeln
wa_po = corresponding #( wa_ekpo ).
append wa_po to it_po.
endif.
endloop.
endif.
endloop.
get time stamp field l_end.
l_result_para = l_end - l_start.
nrec = lines( it_po ).
write :/ '(Parallel Cursor)'.
write :/ '#Records:', nrec, 'Time:', l_result_para, 'seconds'.
skip.
if l_result_nest < l_result_para.
l_winner = 'NESTED LOOP IS'.
else.
l_winner = 'PARALLEL CURSOR IS'.
endif.
l_compare = ( l_result_nest - l_result_para ) / l_result_nest * 100.
WRITE: / l_winner, l_compare, '% FASTER!'.Here’s the testing result I get after comparing both methods.
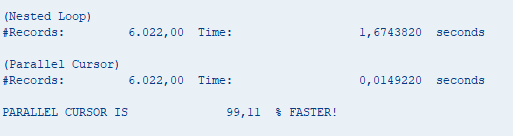
Conclusion?
Surely, Parallel Cursor drastically reduces the number of iterations, solving the inefficiencies of the nested loop. This makes it an ideal solution for large datasets, improving runtime performance by up to 99%.
But on a side note, you can also improve nested loop performance significantly by using SORTED TABLE type because of its built in binary search algorithm. Learn also about Types of Internal Table.
Share this tutorial with Fellow Geeks!